Modern bioinformatics research is characterized by the constant emergence of complex data sources and analytical challenges. Researchers routinely confront tasks that require the synthesis of diverse datasets, the execution of iterative analyses, and the interpretation of subtle biological signals. High-throughput sequencing, multi-dimensional imaging, and other advanced data collection techniques contribute to an environment where traditional, simplistic evaluation methods fall short. Current benchmarks for artificial intelligence often emphasize recall or limited multiple-choice formats, which do not fully capture the nuanced, multi-step nature of real-world scientific investigations. As a result, despite progress in many areas of AI, there remains a critical need for methods that more accurately reflect the iterative and exploratory process that defines bioinformatics.
Introducing BixBench – A Thoughtful Approach to Benchmarking
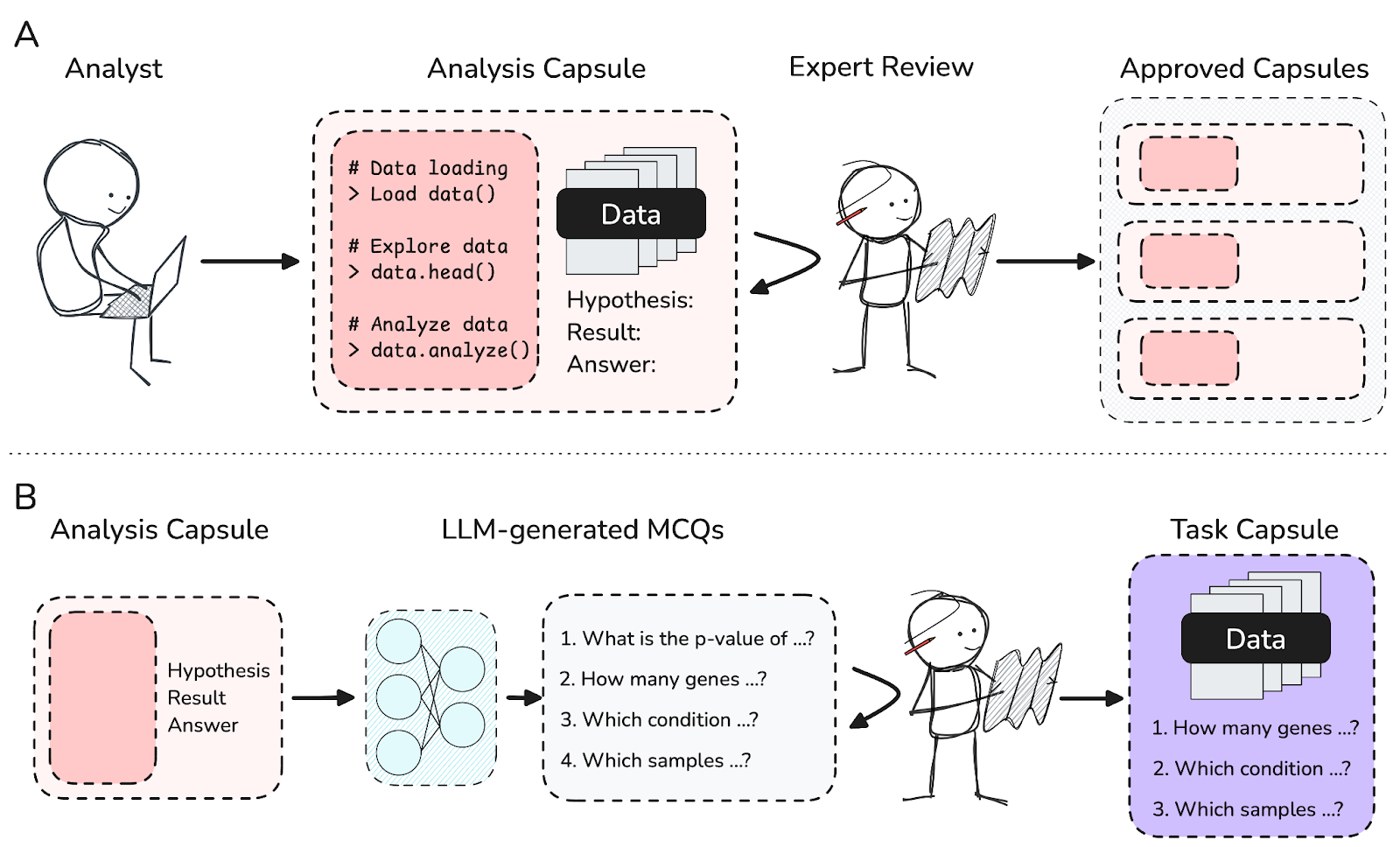
In response to these challenges, researchers from FutureHouse and ScienceMachine have developed BixBench—a benchmark designed to evaluate AI agents on tasks that closely mirror the demands of bioinformatics. BixBench comprises 53 analytical scenarios, each carefully assembled by experts in the field, along with nearly 300 open-answer questions that require a detailed and context-sensitive response. The design process for BixBench involved experienced bioinformaticians reproducing data analyses from published studies. These reproduced analyses, organized into “analysis capsules,” serve as the foundation for generating questions that require thoughtful, multi-step reasoning rather than simple memorization. This method ensures that the benchmark reflects the complexity of real-world data analysis, offering a robust environment to assess how well AI agents can understand and execute intricate bioinformatics tasks.

Technical Aspects and Advantages of BixBench
BixBench is structured around the idea of “analysis capsules,” which encapsulate a research hypothesis, associated input data, and the code used to carry out the analysis. Each capsule is constructed using interactive Jupyter notebooks, promoting reproducibility and mirroring everyday practices in bioinformatics research. The process of capsule creation involves several steps: from initial development and expert review to automated generation of multiple questions using advanced language models. This multi-tiered approach helps ensure that each question accurately reflects a complex analytical challenge.
In addition, BixBench is integrated with the Aviary agent framework, a controlled evaluation environment that supports essential tasks such as code editing, data directory exploration, and answer submission. This integration allows AI agents to follow a process that is similar to that of a human bioinformatician—exploring data, iterating over analyses, and refining conclusions. The careful design of BixBench means that it not only tests the ability of an AI to generate correct answers, but also its capacity to navigate through a series of complex, interrelated tasks.

Insights from the BixBench Evaluation
When current AI models were evaluated using BixBench, the results underscored the significant challenges that remain in developing robust data analysis agents. In tests conducted with two advanced models—GPT-4o and Claude 3.5 Sonnet—the open-answer tasks yielded an accuracy of approximately 17% at best. When the models were presented with multiple-choice questions derived from the same analysis capsules, their performance was only marginally better than random selection.
These outcomes highlight a persistent difficulty: current models struggle with the layered nature of real-world bioinformatics challenges. Issues such as interpreting complex plots and managing diverse data formats remain problematic. Furthermore, the evaluation involved multiple iterations to capture the variability in each model’s performance, revealing that even slight changes in task execution can lead to divergent results. Such findings suggest that while modern AI systems have advanced in code generation and basic data manipulation, they still have considerable room for improvement when tasked with the subtle and iterative process of scientific inquiry.

Conclusion – Reflections on the Path Forward
BixBench represents a measured step forward in our efforts to create more realistic benchmarks for AI in scientific data analysis. This benchmark, with its 53 analytical scenarios and close to 300 associated questions, offers a framework that is well aligned with the challenges of bioinformatics. It assesses not just the ability to recall information, but the capacity to engage in multi-step analysis and to produce insights that are directly relevant to scientific research.
The current performance of AI models on BixBench suggests that there is significant work ahead before these systems can be relied upon to perform autonomous data analysis at a level comparable to expert bioinformaticians. Nonetheless, the insights gained from BixBench provide a clear direction for future research. By focusing on the iterative and exploratory nature of data analysis, BixBench encourages the development of AI agents that can not only answer predefined questions but also support the discovery of new scientific insights through thoughtful, step-by-step reasoning.
Check out the Paper, Blog and Dataset. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.
🚨 Recommended Read- LG AI Research Releases NEXUS: An Advanced System Integrating Agent AI System and Data Compliance Standards to Address Legal Concerns in AI Datasets
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.



















