
Object-centric learning (OCL) is an area of computer vision that aims to decompose visual scenes into distinct objects, enabling advanced vision tasks such as prediction, reasoning, and decision-making. Traditional methods in visual recognition often rely on feature extraction without explicitly segmenting objects, which limits their ability to understand object relationships. In contrast, OCL models break down images into object-level representations, making them more effective for tasks requiring object interactions. This approach is inspired by human vision, which naturally separates objects in a scene to facilitate understanding. OCL models contribute to fields such as robotics, autonomous systems, and intelligent image processing by focusing on object-level information.
One of the fundamental challenges in OCL is the accurate reconstruction of objects in visually complex environments. Existing methods rely heavily on pixel-based self-supervision, which often struggles with intricate textures, resulting in poor object segmentation. The problem becomes more pronounced when dealing with natural scenes, where objects do not have distinct boundaries. While some approaches attempt to mitigate this by reconstructing optical flow or depth maps, these solutions require additional computational resources and manual annotations, making them less scalable. The difficulty lies in creating an approach that can effectively separate and reconstruct objects while maintaining computational efficiency.
Several methods have been developed to improve OCL performance, each with limitations. Variational Autoencoders (VAEs) have been used to encode image representations, but their reliance on pixel reconstruction leads to challenges in handling complex textures. Other approaches utilize Vision Foundation Models (VFMs), which extract better object-level features, but their integration into OCL frameworks has remained limited. Some models use pretrained convolutional networks such as ResNet, but these cannot fully capture object-centric representations. More recent efforts have explored transformer-based architectures to enhance segmentation accuracy but still struggle with efficient reconstruction. The need for a more integrated and structured OCL approach remains unresolved.
Researchers from Aalto University in Finland introduced Vector-Quantized Vision Foundation Models for Object-Centric Learning (VQ-VFM-OCL or VVO) to address these challenges. This framework fully integrates VFMs into OCL by extracting high-quality object representations and quantizing them to enhance supervision in reconstruction. Unlike previous models that treat VFMs as passive feature extractors, VVO leverages them to improve feature aggregation and rebuilding. By incorporating vector quantization, the method ensures that object features remain consistent across different instances, enhancing performance. The architecture of VVO is designed to unify various OCL methodologies into a more structured framework, allowing it to work seamlessly across different vision tasks.
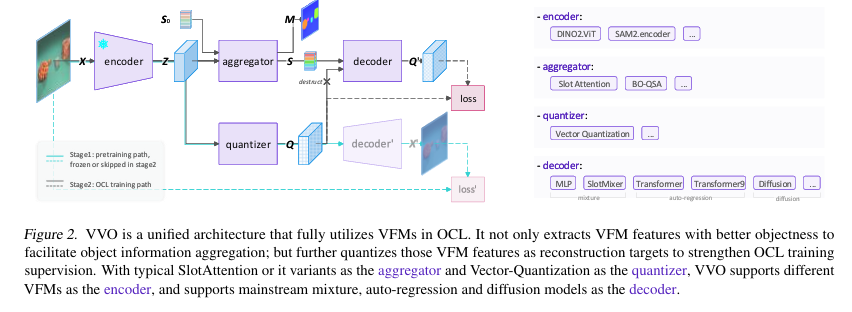
The VVO framework consists of multiple components that function together to improve OCL performance. The encoder extracts feature maps from VFMs, generating a dense feature representation of an image. The aggregator then processes this representation, which employs Slot Attention to segment objects into distinct feature vectors. Unlike traditional OCL models, VVO introduces a quantization mechanism that refines these features, ensuring they remain stable across different images. The decoder then reconstructs the original image from the quantized features, providing a structured learning signal. This method improves object segmentation and reduces redundancy, making feature extraction more efficient. Moreover, VVO supports multiple OCL decoding strategies, including mixture-based, autoregressive, and diffusion-based models, making it a versatile solution for different applications.
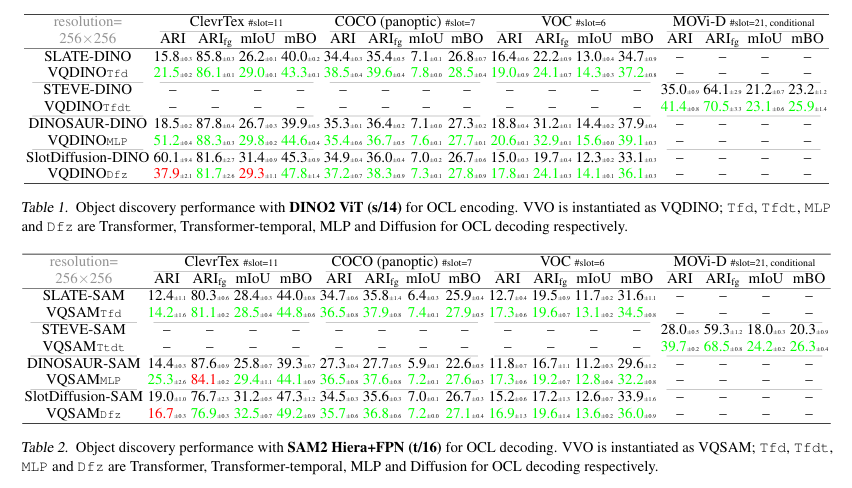
Experiments demonstrated that VVO significantly outperforms existing OCL approaches in object discovery and related tasks. The framework was tested on multiple datasets, including COCO and MOVi-D, achieving higher segmentation accuracy than state-of-the-art methods. On COCO, VVO improved adjusted Rand Index (ARI) scores by achieving 38.5, while foreground ARI scores reached 39.6. The model also exhibited significant improvements in mean Intersection-over-Union (mIoU) and mean Best Overlap (mBO), with values of 7.8 and 28.5, respectively. In comparison, existing models such as DINOSAUR and SlotDiffusion showed lower performance in these metrics. Further, VVO demonstrated its effectiveness in video-based tasks, outperforming previous methods in object-centric reasoning and prediction. The framework was also evaluated on YTVIS, a real-world video dataset, where it surpassed prior models in object segmentation accuracy.
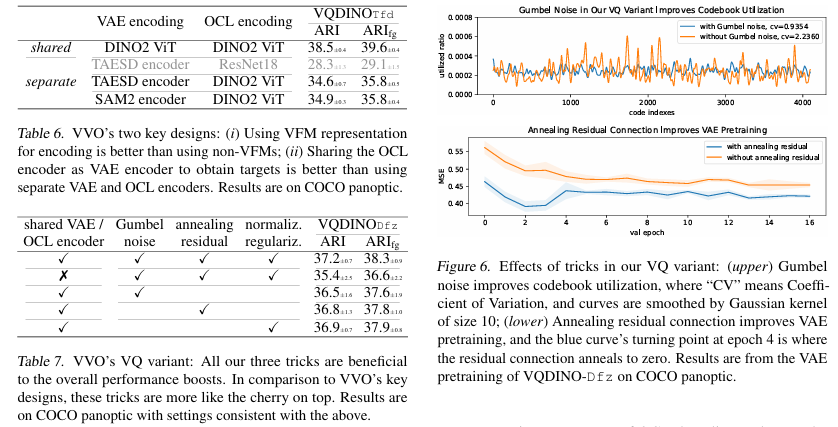
This research presents a significant advancement in object-centric learning by fully integrating VFMs into the learning pipeline. The challenges associated with reconstructing complex textures in OCL are effectively addressed through a structured, quantization-based approach. By ensuring that object representations remain stable and distinct across different images, VVO enhances both segmentation accuracy and reconstruction efficiency. The framework’s ability to support multiple decoding strategies further adds flexibility. Given its superior performance across various datasets, VVO represents a promising direction for future developments in OCL. Its application in robotics, autonomous navigation, and intelligent surveillance could lead to further innovations in visual learning systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.
🚨 Recommended Read- LG AI Research Releases NEXUS: An Advanced System Integrating Agent AI System and Data Compliance Standards to Address Legal Concerns in AI Datasets
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.



















